Comparing the performance of MongoDB vs. PostgreSQL. Part II: Index
Continued from here.
For this experiment, we created indexes on the fields id and floatvalue (text fields lowered, the topic full-text index will not affect as it is material for another article). As the queries used samples from the ranges:
the
But first, you must assess how much speed fell inserting after adding of indexes. For this, we will add another 250 000 records in MongoDB and POstgreSQL.
MongoDB
the
PostgreSQL
the
After simple calculations, we can understand that the speed of insert of MongoDB remained the undisputed leader: after adding indexes its insertion speed fell by only ~10% and made 3600 items per second. While the speed of inserts from PostgreSQL fell on ~30% was about 536 records per second.
I would like to see a sample formed in the same way. Execute the following queries:
MongoDB
PostgreSQL
However, after comparing the speed of execution of operations, the situation on the samples changed in favor of PostgreSQL:

It is also worth noting that the sample is not out of range, and with specific digits (e.g.
Another revelation was that when using indexes in MongoDB so dramatically reduces the consumption of CPU time (up to 1-2 % vs 30-40 % when searching without indexing), which is even ahead in this PostgreSQL (down to 4-14 % vs. 5-25 %).
Before we summarize, share, as promised resulting plaque and diagrams of resource consumption by queries:

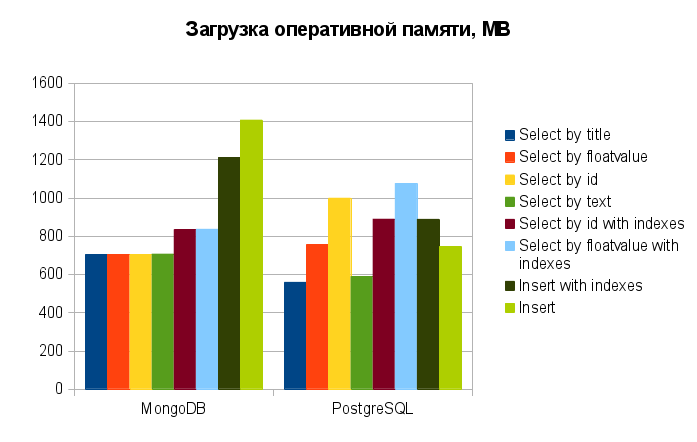
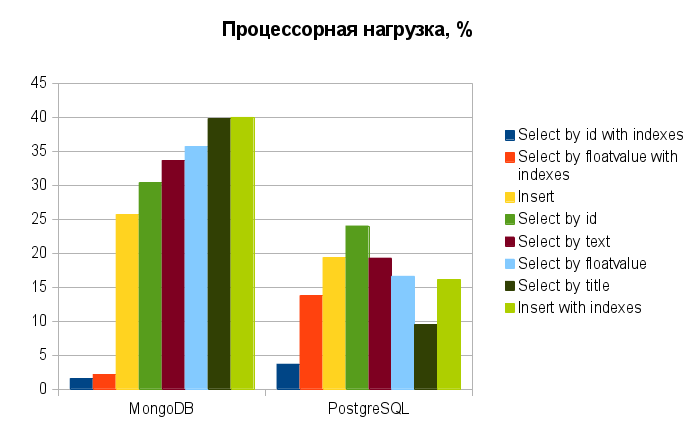
And now for the results.
The naked eye can immediately see one advantage of MongoDB prior to PostgreSQL: insertion speed. It is almost an order of magnitude higher as using indexes and without them. Moreover, the use of indexes is not so much impact (just ~10% against 30% reduction from PostgreSQL). It is really an excellent result! But how often do you use the insert relative to the sample (over all conditions)?
When sampling from a collection without indexes, MongoDB also a leader, although not as much. Nice! But how often do you work with tables without indexes?
Do not think that their questions I'm trying to turn you away from noSQL database. Tables without indexes (mean primary) are the place to be in those or other decisions. Speed priority inserts for some of the tasks are also very real and, moreover, sometimes very popular. The question is, whether it is you specifically? Specifically for your current task? This (very superficial) testing was not intended to answer, I must admit, quite a popular question "Which is better SQL or noSQL?". It is intended to bring you to reflection, to assess the needs and capabilities when choosing a solution for a particular problem.
Finally I will say that for example, we use both types of DBMS depending on the data structures, objectives and options with them. An integrated approach is much better and allows the most optimal to work with any data.
Article based on information from habrahabr.ru
Experiment II: Index
For this experiment, we created indexes on the fields id and floatvalue (text fields lowered, the topic full-text index will not affect as it is material for another article). As the queries used samples from the ranges:
the
-
the
- 10 000 < id < 100 000
200 000 < floatvalue < 300 000
But first, you must assess how much speed fell inserting after adding of indexes. For this, we will add another 250 000 records in MongoDB and POstgreSQL.
MongoDB
the
Insert 250000 records complete! Total time: 69.453 sec
PostgreSQL
the
psql -d prefTest -f 250k.p5.sql (Total time: 466.153 sec)
After simple calculations, we can understand that the speed of insert of MongoDB remained the undisputed leader: after adding indexes its insertion speed fell by only ~10% and made 3600 items per second. While the speed of inserts from PostgreSQL fell on ~30% was about 536 records per second.
I would like to see a sample formed in the same way. Execute the following queries:
MongoDB
-
the
db.tmp.find({$and:[{id:{$gt:10000}},{id:{$lt:100000}}]})
the db.tmp.find({$and:[{floatvalue: {$lt:300000}},{floatvalue: {$gt:200000}}]})
PostgreSQL
-
the
select * from tmp where id > 10000 and id<100000
the select * from tmp where floatvalue<300000 & floatvalue>200000
However, after comparing the speed of execution of operations, the situation on the samples changed in favor of PostgreSQL:
It is also worth noting that the sample is not out of range, and with specific digits (e.g.
floatvalue=1234567.76545) both DBMS showed the result in 0 milliseconds. Therefore, these operations here are not even considered. This is the question of the reasonable use of the indexes in accordance with the proposed conditions of the sample. Here, the indexes and the queries used for the sole purpose of load testing.Another revelation was that when using indexes in MongoDB so dramatically reduces the consumption of CPU time (up to 1-2 % vs 30-40 % when searching without indexing), which is even ahead in this PostgreSQL (down to 4-14 % vs. 5-25 %).
Results
Before we summarize, share, as promised resulting plaque and diagrams of resource consumption by queries:
And now for the results.
The naked eye can immediately see one advantage of MongoDB prior to PostgreSQL: insertion speed. It is almost an order of magnitude higher as using indexes and without them. Moreover, the use of indexes is not so much impact (just ~10% against 30% reduction from PostgreSQL). It is really an excellent result! But how often do you use the insert relative to the sample (over all conditions)?
When sampling from a collection without indexes, MongoDB also a leader, although not as much. Nice! But how often do you work with tables without indexes?
Do not think that their questions I'm trying to turn you away from noSQL database. Tables without indexes (mean primary) are the place to be in those or other decisions. Speed priority inserts for some of the tasks are also very real and, moreover, sometimes very popular. The question is, whether it is you specifically? Specifically for your current task? This (very superficial) testing was not intended to answer, I must admit, quite a popular question "Which is better SQL or noSQL?". It is intended to bring you to reflection, to assess the needs and capabilities when choosing a solution for a particular problem.
Finally I will say that for example, we use both types of DBMS depending on the data structures, objectives and options with them. An integrated approach is much better and allows the most optimal to work with any data.



Комментарии
Отправить комментарий