Testing Amazon SQS
In a network there are already several reviews of the performance of this solution from Amazon, in this article, I did not pursue the goal of validation of the obtained results, I was interested in some features not covered in other sources, namely:
The support library for AWS in erlang is erlcloud [1], to initialize the library, you simply call methods start and configure, as indicated on github. My posts will contain a set of random characters generated by the following function:
the
to measure speed we use the famous function using timer:tc, but with some changes:
the
the changes relate to the calling test functions in this version I added the argument R, which allows you to use the value returned on a previous run, this is necessary in order to generate the message numbers and collect additional information on the mixing upon receipt of the message. Therefore, the function of sending a message with number will look as follows:
the
And her challenge with the collection of statistics:
the
here 31 — the number of the first message, the number is not chosen randomly, the fact that erlang is not too well distinguish between sequences of numbers and strings, and in the message it will be a symbol number 31, smaller numbers can be passed to SQS, but contiguous ranges are small (#x9 | #xA | #xD | [#x20 to #xD7FF] | [#xE000 to #xFFFD] | [#x10000 to #x10FFFF], details [2]) and at the exit from the allowed range you will get an exception. Therefore, the function send_random generates and sends a message to the queue named Queue, the beginning of which is the number identifying the number, the function returns the number of the next number, which is used then the following generation function. Function test_avg takes QueueName, which becomes the second argument of the function send_random, the first argument number and the number of repetitions.
A function that will receive messages and check their order will look as follows:
the
Deleting messages:
the
in the list that is passed to delete contains a lot of unnecessary information (message body, etc.), delete function finds receipt_handle, which is required for formation of the request or returns wrong if receipt_handle not found
Looking ahead, I can say that even on a small number of messages, the stirring was quite substantial and there was an additional objective: to assess the degree of mixing. Unfortunately a good criteria could not be found and it was decided to display the maximum and average deviation from the correct position. Knowing the size of this window, you can restore the order of messages upon receipt, of course, deteriorating the processing speed.
To calculate this difference is enough to change only one function of checking the order of messages:
the
call function run-series will look like the following:
the
I get the number of elements that came later than you need the sum of their distances from the largest of the received elements and the maximum displacement. Most interesting to me here is the maximum displacement, the other characteristics can be called controversial, and they're probably not too successfully calculated (for example, if one item is read before all the elements that should go before it will be considered misplaced in this case). To results:
the
The first line is the number of messages in the queue, and the second maximum displacement, and the third is the mean offset.
The results surprised me, the message isn't just mixed, it simply has no boundaries, that is, with the increase of the number of messages we need to increase the size of the viewable window. The same as a graph:
As I wrote, Amazon SQS does not support subscriptions, you can use Amazon SNS, but if you need a quick queue with multiple processors is not suitable, in order not to pull method of receiving messages Amazon implemented Long Polling, which allows you to hang, waiting for messages to twenty seconds, and since SQS is charged by the number of called methods that would significantly reduce the cost of queue, but what is the problem: for a small number of messages (according to the official documentation) would not return anything. This behavior is critical for queues that require you to react quickly to an event, and generally speaking, if this happens often then Long Polling does not make much sense, as it becomes equivalent to periodic surveys with a reaction time of SQS.
To test, create two processes, one of which will be at random times, send messages, and the second to reside in Long Polling, the moments of sending and receiving messages will be stored for later comparison. In order to enable this mode, set the Receive Message Wait Time = 20 seconds in the queue settings.
the
this function sleeps for a random number of milliseconds, and then remembers the moment and sends the message
the
these two functions allow you to retrieve messages and to remember the moments in which it happened. After the simultaneous performance of these functions by means of the spawn I get two lists, the difference between which shows the response time to a message. It fails to recognize that the messages can get mixed up, the whole thing was just to further increase reaction time.
Let's see what happened:
the
the first line is the value exhibited the maximum delay of the sending process. That is: 10 seconds, 7.5 seconds... the Rest of the line — minimum, maximum, and average waiting time the message was received.
The same as a graph:

The average time turned out the same in every case, we can say that, on average, between the sending of single messages until their receipt is two seconds. Long enough. In this test, the sample was quite small, 20, this min-max values is rather a matter of luck, rather than some kind of dependence.
First check how important the effect of “warming up” of the queue when sending messages:
the
The same as a graph:

we can say that no warming is not observed, that is, the queue behaves about the same on these volumes of data, only the maximum somehow increased, but the average and minimum remain in place.
Same for reading
the

There is also no saturation, the average in the area of 200ms. Sometimes the reading was immediate (faster than 1ms), but this means that the message has not been received, according to the documentation, the server SQS can do that, you just need to request the message again.
Proceed directly to block and multi-threaded testing
Unfortunately, the erlcloud library contains functions for batch messaging, but such features are not difficult to implement at existing in functions sending a message you need to change the query to the following:
the
and to finish the function of a query:
the
the library should also fix the version of the API for example on 2011-10-01, otherwise Amazon will return Bad request in response to your requests.
test functions similar to those used in other tests:
the
Here only had to change the message length so that the entire package fit into 64KB, otherwise an exception is thrown.
The following data were obtained for the record:
the
here 0 means read one in 1 stream, followed by 1 reading 10 in 1 torrent 10 2 torrent 10 4 threads and so on
To read:
the
the graphs showing the throughput for read and write (messages per second)

Blue color — recording, red — read.
From these data we can conclude that the maximum throughput is achieved for district 10 threads and read about 50, with a further increase of the number of threads the given number of messages per unit time is not increased.
It turns out that Amazon SQS significantly changes the order of messages is not a very good response time and throughput, to counter this, you can only reliability and small (in the case of a small number of messages) fee. That is, if you don't speed critical, no matter what the message mixed up and you don't want to administer or hire a server administrator queues — it's your choice.
Article based on information from habrahabr.ru
-
the
- in the documentation it is said that Amazon tries to keep the order of the posts, how well will it last? the
- how quickly does receive a message when using Long Polling? the
- as far as speeds up the process of batch processing?
problem Statement
The support library for AWS in erlang is erlcloud [1], to initialize the library, you simply call methods start and configure, as indicated on github. My posts will contain a set of random characters generated by the following function:
the
random_string(0) -> [];
random_string(Length) -> [random_char() | random_string(Length-1)].
random_char () - > random:uniform(95) + 31 .
to measure speed we use the famous function using timer:tc, but with some changes:
the
test_avg(M, F, A, R, N) when N > 0 ->
{Ret, L} = test_loop(M, F, A, R, N, []),
Length = length(L),
Min = lists:min(L),
Max = lists:max(L),
Med = lists:nth(round((Length / 2)), lists:sort(L)),
Avg = round(lists:foldl(fun(X, Sum) - > X + Sum end, 0, L) / Length),
io:format("Range: ~b - ~b mics~n"
"Median: ~b mics~n"
"Average: ~b mics~n",
[Min, Max, Med, Avg]),
Ret.
test_loop(_M, _F, _A, R, 0, List) ->
{R, List};
test_loop(M, F, A, R, N, List) ->
{T, Result} = timer:tc(M, F, [R|A]),
test_loop(M, F, A, Result, N - 1, [T|List]).
the changes relate to the calling test functions in this version I added the argument R, which allows you to use the value returned on a previous run, this is necessary in order to generate the message numbers and collect additional information on the mixing upon receipt of the message. Therefore, the function of sending a message with number will look as follows:
the
send_random(N, Queue) ->
erlcloud_sqs:send_message(Queue, [N + 1 | random_string(6000 + random:uniform(6000))]),
N + 1 .
And her challenge with the collection of statistics:
the
test_avg(?MODULE send_random, [QueueName], 31, 20)
here 31 — the number of the first message, the number is not chosen randomly, the fact that erlang is not too well distinguish between sequences of numbers and strings, and in the message it will be a symbol number 31, smaller numbers can be passed to SQS, but contiguous ranges are small (#x9 | #xA | #xD | [#x20 to #xD7FF] | [#xE000 to #xFFFD] | [#x10000 to #x10FFFF], details [2]) and at the exit from the allowed range you will get an exception. Therefore, the function send_random generates and sends a message to the queue named Queue, the beginning of which is the number identifying the number, the function returns the number of the next number, which is used then the following generation function. Function test_avg takes QueueName, which becomes the second argument of the function send_random, the first argument number and the number of repetitions.
A function that will receive messages and check their order will look as follows:
the
checkorder(N, []) -> N;
checkorder(N, [H | T]) ->
[{body, [M | _]}|_] = H,
K = if M > N> M;
true - > io:format("Wrong ~b less than ~b~n", [M, N]),
N
end
checkorder(K, T).
receive_checkorder(LastN, Queue) ->
[{messages, List} | _] = erlcloud_sqs:receive_message(Queue),
remove_list(Queue, List),
checkorder(LastN, List).
Deleting messages:
the
remove_msg(_, []) -> wrong;
remove_msg(Q, [{receipt_handle, Handle} | _]) -> erlcloud_sqs:delete_message(Q, Handle);
remove_msg(Q, [_ | T]) -> remove_msg(Q, T).
remove_list (_, []) - > ok;
remove_list(Q, [H | T]) -> remove_msg(Q, H), remove_list(Q, T).
in the list that is passed to delete contains a lot of unnecessary information (message body, etc.), delete function finds receipt_handle, which is required for formation of the request or returns wrong if receipt_handle not found
Mixing messages
Looking ahead, I can say that even on a small number of messages, the stirring was quite substantial and there was an additional objective: to assess the degree of mixing. Unfortunately a good criteria could not be found and it was decided to display the maximum and average deviation from the correct position. Knowing the size of this window, you can restore the order of messages upon receipt, of course, deteriorating the processing speed.
To calculate this difference is enough to change only one function of checking the order of messages:
the
checkorder(N, []) -> N;
checkorder({N, Cnt, Sum, Max}, [H | T]) ->
[{body, [M | _]}|_] = H,
{N1, Cnt1, Sum1, Max1} = if M < N>
{N, Cnt + 1, Sum + N - M, if Max < N - M> N - M; true - > Max end };
true -> {M, Cnt, Sum, Max}
end
checkorder({N1, Cnt1, Sum1, Max1}, T).
call function run-series will look like the following:
the
{_, Cnt, Sum, Max} = test_avg(?MODULE receive_checkorder, [QueueName], {0, 0, 0, 0}, Size)
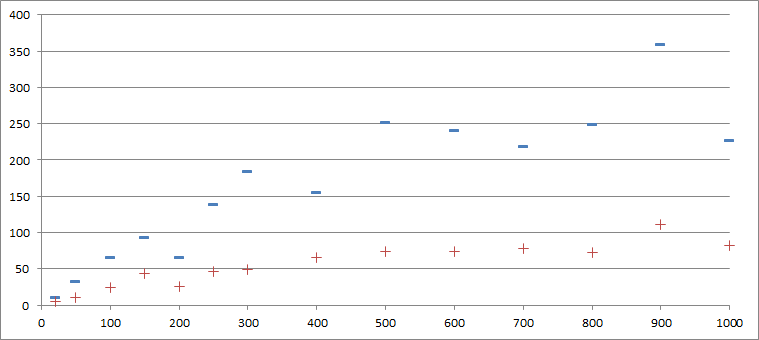
I get the number of elements that came later than you need the sum of their distances from the largest of the received elements and the maximum displacement. Most interesting to me here is the maximum displacement, the other characteristics can be called controversial, and they're probably not too successfully calculated (for example, if one item is read before all the elements that should go before it will be considered misplaced in this case). To results:
| Size (PCs) | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| the Maximum offset (PC) | 11 | 32 | 66 | 93 | 65 | 139 | 184 | 155 | 251 | 241 | 218 | 249 | 359 | 227 |
| Secondary offset (PCs) | 5.3 | 10.5 | 23.9 | 43 | 25.6 | 45.9 | 48.4 | 65.6 | 74.2 | 74.2 | 78.3 | 72.3 | 110.8 | 82.8 |
The first line is the number of messages in the queue, and the second maximum displacement, and the third is the mean offset.
The results surprised me, the message isn't just mixed, it simply has no boundaries, that is, with the increase of the number of messages we need to increase the size of the viewable window. The same as a graph:
Long Polling
As I wrote, Amazon SQS does not support subscriptions, you can use Amazon SNS, but if you need a quick queue with multiple processors is not suitable, in order not to pull method of receiving messages Amazon implemented Long Polling, which allows you to hang, waiting for messages to twenty seconds, and since SQS is charged by the number of called methods that would significantly reduce the cost of queue, but what is the problem: for a small number of messages (according to the official documentation) would not return anything. This behavior is critical for queues that require you to react quickly to an event, and generally speaking, if this happens often then Long Polling does not make much sense, as it becomes equivalent to periodic surveys with a reaction time of SQS.
To test, create two processes, one of which will be at random times, send messages, and the second to reside in Long Polling, the moments of sending and receiving messages will be stored for later comparison. In order to enable this mode, set the Receive Message Wait Time = 20 seconds in the queue settings.
the
send_sleep(L, Queue) ->
timer:sleep(random:uniform(10000)),
Call = erlang:now(),
erlcloud_sqs:send_message(Queue, random_string(6000 + random:uniform(6000))),
[Call | L].
this function sleeps for a random number of milliseconds, and then remembers the moment and sends the message
the
remember_moment(L, []) -> L;
remember_moment(L, [ _ | _ ]) - > [erlang:now() | L].
receive_polling(L, Queue) ->
[{messages, List} | _] = erlcloud_sqs:receive_message(Queue),
remove_list(Queue, List),
remember_moment(L, List).
these two functions allow you to retrieve messages and to remember the moments in which it happened. After the simultaneous performance of these functions by means of the spawn I get two lists, the difference between which shows the response time to a message. It fails to recognize that the messages can get mixed up, the whole thing was just to further increase reaction time.
Let's see what happened:
| Interval falling asleep | 10000 | 7500 | 5000 | 2500 |
|---|---|---|---|---|
| Minimum time (sec) | 0.28 | 0.27 | 0.66 | |
| Maximum time (sec) | 10.25 | 7.8 | 5.36 | 5.53 |
| Average time (sec) | 1.87 | 1.87 | 1.84 | 1.88 |
the first line is the value exhibited the maximum delay of the sending process. That is: 10 seconds, 7.5 seconds... the Rest of the line — minimum, maximum, and average waiting time the message was received.
The same as a graph:
The average time turned out the same in every case, we can say that, on average, between the sending of single messages until their receipt is two seconds. Long enough. In this test, the sample was quite small, 20, this min-max values is rather a matter of luck, rather than some kind of dependence.
Batch upload
First check how important the effect of “warming up” of the queue when sending messages:
| Number of records | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Minimum time (sec) | 0.1 | 0.1 | 0.1 | 0.09 | 0.09 | 0.09 | 0.09 | 0.1 | 0.09 | 0.1 | 0.1 | 0.09 | 0.09 | 0.09 |
| Maximum time (sec) | 0.19 | 0.37 | 0.41 | 0.41 | 0.37 | 0.38 | 0.37 | 0.43 | 0.39 | 0.66 | 0.74 | 0.48 | 0.53 | 0.77 |
| Average time (sec) | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 | 0.12 |
The same as a graph:
we can say that no warming is not observed, that is, the queue behaves about the same on these volumes of data, only the maximum somehow increased, but the average and minimum remain in place.
Same for reading
| Number of records | 20 | 50 | 100 | 150 | 200 | 250 | 300 | 400 | 500 | 600 | 700 | 800 | 900 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Minimum time (sec) | 0.001 | 0.14 | 0 | 0.135 | 0 | 0.135 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Maximum time (sec) | 0.72 | 0.47 | 0.65 | 0.65 | 0.69 | 0.51 | 0.75 | 0.75 | 0.76 | 0.73 | 0.82 | 0.79 | 0.74 | 0.91 |
| Average time (sec) | 0.23 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.21 | 0.2 | 0.2 | 0.2 | 0.2 | 0.21 |
There is also no saturation, the average in the area of 200ms. Sometimes the reading was immediate (faster than 1ms), but this means that the message has not been received, according to the documentation, the server SQS can do that, you just need to request the message again.
Proceed directly to block and multi-threaded testing
Unfortunately, the erlcloud library contains functions for batch messaging, but such features are not difficult to implement at existing in functions sending a message you need to change the query to the following:
the
Doc = sqs_xml_request(Config QueueName, "SendMessageBatch",
encode_message_list(Messages, 1)),
and to finish the function of a query:
the
encode_message_list ([],_) - > [];
encode_message_list([H | T], N) ->
MesssageId = string:concat("SendMessageBatchRequestEntry.", integer_to_list(N)),
[{string:concat(MesssageId, ".Id"), integer_to_list(N)}, {string:concat(MesssageId, ".MessageBody"), H} | encode_message_list(T, N + 1)].
the library should also fix the version of the API for example on 2011-10-01, otherwise Amazon will return Bad request in response to your requests.
test functions similar to those used in other tests:
the
gen_messages(0) -> [];
gen_messages(N) - > [random_string(5000 + random:uniform(1000)) | gen_messages(N - 1)].
send_batch(N, Queue) ->
erlang:display(erlcloud_sqs:send_message_batch(Queue, gen_messages(10))),
N + 1 .
Here only had to change the message length so that the entire package fit into 64KB, otherwise an exception is thrown.
The following data were obtained for the record:
| Number of threads | 0 | 1 | 2 | 4 | 5 | 10 | 20 | 50 | 100 |
|---|---|---|---|---|---|---|---|---|---|
| Maximum delay (sec) | 0.452 | 0.761 | 0.858 | 1.464 | 1.698 | 3.14 | 5.272 | 11.793 | 20.215 |
| Average latency (sec) | 0.118 | 0.48 | 0.436 | 0.652 | 0.784 | 1.524 | 3.178 | 9.1 | 19.889 |
| Time per message (sec) | 0.118 | 0.048 | 0.022 | 0.017 | 0.016 | 0.016 | 0.017 | 0.019 | 0.02 |
here 0 means read one in 1 stream, followed by 1 reading 10 in 1 torrent 10 2 torrent 10 4 threads and so on
To read:
| Number of threads | 0 | 1 | 2 | 4 | 5 | 10 | 20 | 50 | 100 |
|---|---|---|---|---|---|---|---|---|---|
| Maximum delay (sec) | 0.762 | 2.998 | 2.511 | 2.4 | 2.606 | 2.751 | 4.944 | 11.653 | 18.517 |
| Average latency (sec) | 0.205 | 1.256 | 1.528 | 1.566 | 1.532 | 1.87 | 3.377 | 7.823 | 17.786 |
| Time per message (sec) | 0.205 | 0.126 | 0.077 | 0.04 | 0.031 | 0.02 | 0.019 | 0.017 | 0.019 |
the graphs showing the throughput for read and write (messages per second)
Blue color — recording, red — read.
From these data we can conclude that the maximum throughput is achieved for district 10 threads and read about 50, with a further increase of the number of threads the given number of messages per unit time is not increased.
Conclusions
It turns out that Amazon SQS significantly changes the order of messages is not a very good response time and throughput, to counter this, you can only reliability and small (in the case of a small number of messages) fee. That is, if you don't speed critical, no matter what the message mixed up and you don't want to administer or hire a server administrator queues — it's your choice.
Links
-
the
- Erlcloud on github github.com/gleber/erlcloud the
- www.w3.org/TR/REC-xml/#charsets



Комментарии
Отправить комментарий