The search system in the NSA contain more than 850 billion records
In the framework of the project, The Intercept published the next portion of the documents provided by Edward Snowden to the media. These documents outline the search engine ICReach working at the NSA.

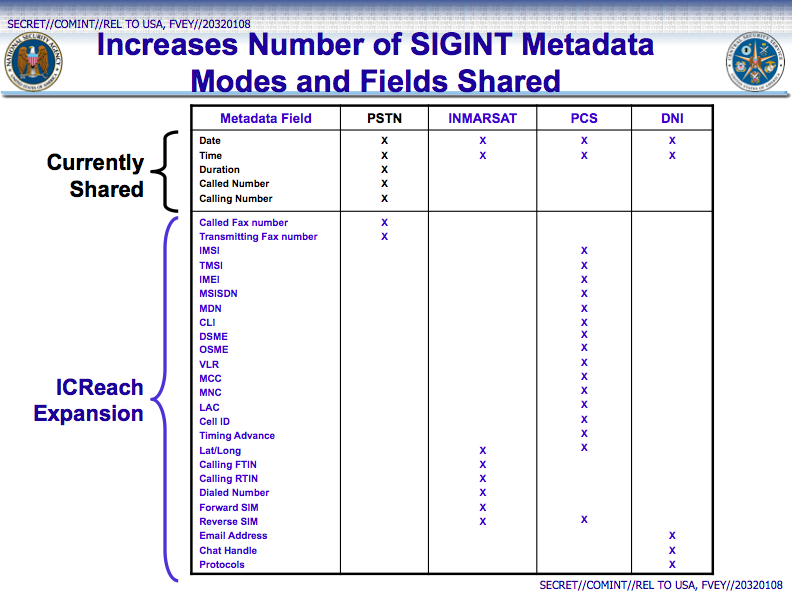
Search engine, as described in prezentaciiequipped with a simple interface similar to Google. She performs a full text search on more than 850 billion records with confidential information: this metadata of phone calls (dialed numbers, time and place of the call), email (names of sender and recipient, time of sending), and Internet chats, faxes, coordinates, cell phones, etc. (total of 30 types of data).
Although the system does not index the actual text of messages and metadata only, but it is also very valuable information for intelligence. For example, you can quickly compile a list of all the people who called a particular phone number during the year. Or make a list of all the people who were on a certain street or square from 20:00 to 21:00 and had a mobile phone.
Previously published documents from Snowden talked about the many programs for the mass collection of information that work at the NSA. Now the picture becomes clear how to process this information and how other agencies get access to it.
In memo from 2010 says that the interface ICReach available for more than 1,000 analysts from 23 Federal agencies.
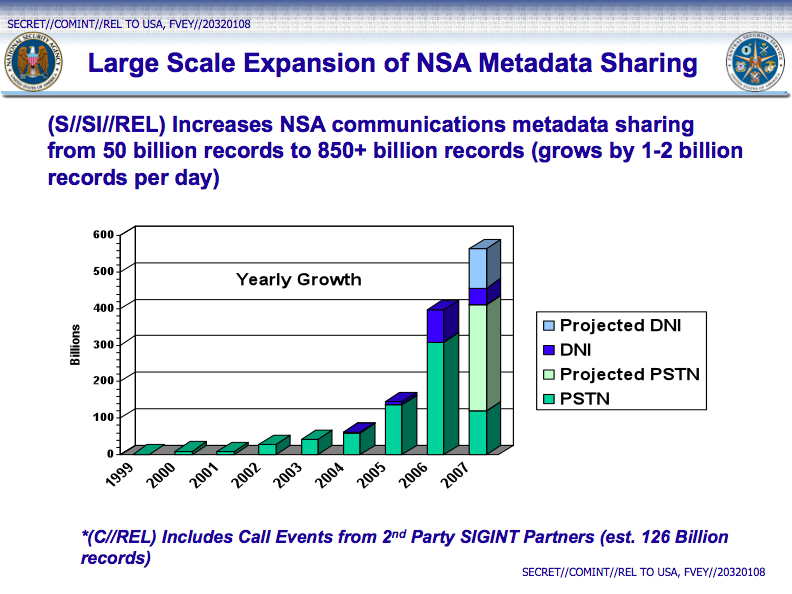
memo from 2007 it is reported that the ICReach system began to develop in 2005, and she greatly expanded the capabilities of the NSA for processing and analysis of data.
"Developers ICReach for the first time provided the intelligence community of the United States access to communications metadata — the document says. — Development began over two years ago with a basic concept, designed to meet the growing demand of the intelligence community on such metadata, and [introduced] the possibility of the NSA for the collection, processing and storage of large amounts of communications metadata related to intelligence around the world." The new engine is designed to replace technologically obsolete systems CRISSCROSS and PROTON, which was launched by the CIA in the 90s.
Search engine designed to add up to 5 billion records every day (in practice, the index was supplemented by 1-2 billion records per day). Apparently, the search engine has indexed the contents of several databases that are replenished independently from each other within the various programmes of interception of communications existing in the NSA.
ICReach pilot program was launched in 2007 and it a 12-fold increase in the volume metadata, that the secret services were divided among themselves.
Initially it was assumed that the service search system will cost from $2.5 million to $4.5 million per year. But in 2010 it was planned to upgrade the system to expand the index beyond 850 billion records, so that the budget could increase.
Article based on information from habrahabr.ru
Search engine, as described in prezentaciiequipped with a simple interface similar to Google. She performs a full text search on more than 850 billion records with confidential information: this metadata of phone calls (dialed numbers, time and place of the call), email (names of sender and recipient, time of sending), and Internet chats, faxes, coordinates, cell phones, etc. (total of 30 types of data).
Although the system does not index the actual text of messages and metadata only, but it is also very valuable information for intelligence. For example, you can quickly compile a list of all the people who called a particular phone number during the year. Or make a list of all the people who were on a certain street or square from 20:00 to 21:00 and had a mobile phone.
Previously published documents from Snowden talked about the many programs for the mass collection of information that work at the NSA. Now the picture becomes clear how to process this information and how other agencies get access to it.
In memo from 2010 says that the interface ICReach available for more than 1,000 analysts from 23 Federal agencies.
memo from 2007 it is reported that the ICReach system began to develop in 2005, and she greatly expanded the capabilities of the NSA for processing and analysis of data.
"Developers ICReach for the first time provided the intelligence community of the United States access to communications metadata — the document says. — Development began over two years ago with a basic concept, designed to meet the growing demand of the intelligence community on such metadata, and [introduced] the possibility of the NSA for the collection, processing and storage of large amounts of communications metadata related to intelligence around the world." The new engine is designed to replace technologically obsolete systems CRISSCROSS and PROTON, which was launched by the CIA in the 90s.
Search engine designed to add up to 5 billion records every day (in practice, the index was supplemented by 1-2 billion records per day). Apparently, the search engine has indexed the contents of several databases that are replenished independently from each other within the various programmes of interception of communications existing in the NSA.
ICReach pilot program was launched in 2007 and it a 12-fold increase in the volume metadata, that the secret services were divided among themselves.
Initially it was assumed that the service search system will cost from $2.5 million to $4.5 million per year. But in 2010 it was planned to upgrade the system to expand the index beyond 850 billion records, so that the budget could increase.



Комментарии
Отправить комментарий